





Addressing the exploding Mobile Learning phenomenon and the evolution of a mobile Adaptive Learning Environment (ALE). ALEs have proven to be effective tools for teaching and for training; however, they have not become common in industrial and organizational settings, in part because their complexity to develop and manage outside of the research lab has been prohibitive. SWIFT is a minimalist ALE that bridges the gap between research and practical application; we successfully simplified research techniques while maintaining as much pedagogic intelligence as possible. This paper and demonstration will explore SWIFT, an example of how a minimalist ALE can be delivered as a viable mobile commercial product supporting ubiquitous learning and the latest standards for interoperability on and offline. We outline some of the issues facing designers of a minimalist system describing the way that research techniques were incorporated; how SWIFT simplifies authoring adaptive learning; standards we have adopted that support tracking and mobility; and how we can use big data for research and analysis to continually improve learner outcomes.
AI Techniques
Years of extensive research and development has been undertaken into applying Artificial Intelligence (AI) techniques to training. The results have proven that more effective training can be achieved through AI. However, the application of AI techniques to teaching and training has not become common in industrial and organizational settings, in part because their complexity has proven difficult to manage outside of the research lab.
SWIFT is the first commercial application of its kind to successfully bridge the gap between research and practical application. This has been accomplished by simplifying the research techniques while striving to maintain as much of the pedagogic intelligence as possible. SWIFT is a minimalist Intelligent Tutoring System (ITS) that uses AI techniques from ITS research in its adaptive testing algorithm, instructional planner and authoring, diagnosis and an AI technique called pattern recognition applied to the short answer question type.
Minimalist Design in SWIFT
The following sections describe the approaches that we have used to make the most of the resources available to the SWIFT ITS. In general, our strategies have taken three paths: first, we have found ways to minimize ITS techniques without compromising too much of their power; second, we have found additional mechanisms to make our solutions more robust; and third, we have taken advantage of the learner-centric model creating technology that supports ubiquitous, non-linear navigation and exploration accessible across all mobile devices on and offline.
Knowledge Representation – SWIFT Authoring
A mobile ALE requires both rich and complex content and an easy way to author, structure, and update ever-changing content. This is especially true with mobile one-on-one eLearning courses that are not reliant on external Instructors or virtual classroom environments. Statistics show that at least 30% of development time is spent on structure and format alone. Add branching to create adaptive learning, and the task becomes overly prohibitive and daunting, hence very few systems offer this level of complexity.
A defining feature of an ITS is a semantic representation of the instructional domain, where concepts are encoded in data structures that allow the system to reason about the course. A minimalist ITS must also employ semantic representation, for an understanding of the concepts in the domain is the basis of much of a system’s intelligent behavior. However, the detail and sophistication of the representation can vary.
We implemented a representation scheme that allows SWIFT to reason about the domain. Instructional design principles provide other criteria for the structure of courses, including a multi-level hierarchy and learning objects that have specific attributes. SWIFT courses are designed in a hierarchical structure that divides the instructional material into smaller and smaller pieces, much as a book does with chapters, sections, and subsections. A course has three levels: the first contains a set of topics, which are divided at the second level into sets of modules, which are divided at the third level into concepts. A semantic representation of the course also allows the specification of dependencies between concepts.
SWIFT authors can easily bundle specific concepts and modules into learning goals. Because of the hierarchical structure of courses built within SWIFT, learning goals can be built incrementally, with the most basic goal appearing first and working up to a more sophisticated level of knowledge attainment. Goals can also be used to adapt content based on job roles, different languages, learning preferences, etc. In practice, the learner can control their own learning path by choosing from among the defined goals, enabling them to decide what they want to learn.
SWIFT Author means more investment can be dedicated to harnessing knowledge by creating rich and deep content to create highly effective mobile adaptive learning courses based on pedagogically sound principles, that does not require branching or structuring the course content.
Adaptive Testing
ITSs gather information about a learner’s progress by observing them as they interact with the learning environment. Many minimalist systems use exercises, quizzes, and exams as the setting for these observations since the range of possible inference about the learner can be more easily constrained. Since many organizations also require that a training system provides concrete records of progress, we chose to use formative and summative testing as our means for observing the learner in SWIFT.
One of the problems with traditional exams is that they are of fixed length; a learner must complete a long series of questions in order for the system to determine how well they know a subject. This characteristic can cause frustration for both novices and experts, who may know after a few questions that the subject matter is either bewildering or trivial. Aside from giving the learner greater control over exams – in that they are never forced to take a test – our primary strategy for tackling the problem of fixed-length exams is adaptive testing. Adaptive testing allows exams to be significantly shorter than traditional tests, without losing any predictive power about a learner’s master of the material. The approach that is implemented in SWIFT is based on the work of [Welch & Frick, 1993]. The algorithm uses Bayes’ theorem to estimate the probability that the learner is a master or non-master of the material after each test question is answered. In SWIFT, novices (non-masters) and experts (masters) can be determined in as few as five questions.
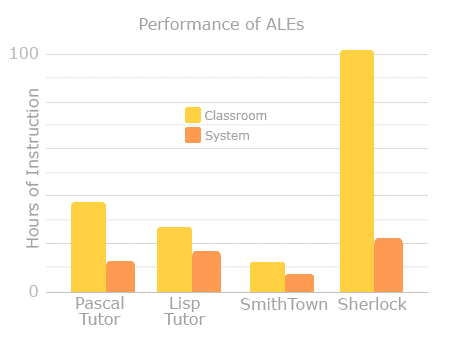
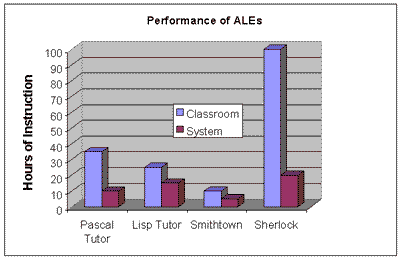
This graph represents the outcomes of a study that was completed comparing classroom instruction to four Intelligent Tutoring Systems. The study looked at (1) whether Tutors engender more effective and efficient learning in relation to traditional formats and (2) do they reduce the range of learning outcomes measures where a majority of individuals are elevated to high performance levels. The Tutors underwent systematic, controlled evaluations: a) Lisp tutor (Anderson Farrell & Sauers, 1984); b) Smithtown (Shute & Glaser, in press); c) Sherlock (Lesgold, Lajoie, Bunzo & Eggan, 1990); and d) The Pascal ITS (Bonar, Cunningham, Beatty & Weil, 1988).
Instructional Planning – the SWIFT ALE
Instructional planning in SWIFT is based on two information sources: the results of an adaptive pretest, and the learner’s choice of one or more goals. Each goal specifies which topics and modules of the course are to be included in the learner’s path; performance on the pretest then indicates whether concepts within those sections are already known and need not be included. Our approach to instructional planning is effective, but is relatively simple compared to some ITSs (e.g. [Becht, 1990]) because of SWIFT’s less-sophisticated domain representation. Since our simpler approach weakens SWIFT’s planning to a degree, we have found other ways of ensuring that appropriate instruction is always available to the learner.
Since we knew that the target population for SWIFT is composed largely of learners that are cooperative and motivated, and we wanted the technology to support a learner-centric model, we were able to view instructional planning as a human-computer problem rather than just a computational one. One of the ways we involve the learner is by providing tools that allow them to monitor their path through the course, and to take control if desired. SWIFT provides an easy to navigate course map that displays the entire course and allows the learner to navigate to any topic of interest. This course map and non-linear approach also ensures that SWIFT is effective for other learning purposes such as, review or just-in-time training. This approach also improves instructional planning by making use of the knowledge of both parties: learners can improve upon or customize the SWIFT course plan if they wish; the recommended path provides support for learners who prefer to follow the SWIFT adapted course path. If the learner navigates using the course path, SWIFT can take them back to where they should be with the click of a button.
Diagnosis
Diagnosis modules attempt to understand problems and misconceptions in a student’s knowledge of the domain (e.g. [Johnson & Soloway, 1985], [McCalla & Greer, 1990] ). Although any student action may be considered, diagnosis is commonly applied to a learner’s answers to test or exercise questions. Diagnosis entails drawing conclusions about the learner’s knowledge based on features in their answers; good diagnosis allows systems to provide appropriate feedback and remediation as well as simple indication of whether an answer is right or wrong. Diagnosis can require significant inferencing power and domain knowledge, which are not the strengths of minimalist systems. An alternative to a fully knowledge-based approach is to detail a number of categories, or cases, of typical errors and misconceptions. Using a case-based approach transforms the inference problem to one of classifications, but effective classification can also be difficult to achieve. One problem occurs in specifying the answers that belong to a particular class. The obvious method is to encode every answer. However, this technique implies that any variation of an answer, even those that do not change its essential parts, must also be included. This can be a daunting task for any but the most trivial of exercises.
An AI technique called pattern recognition was applied to the short answer question type in SWIFT. This approach to the problem allows the author to concentrate on the qualitative differences in the possible answers to a question, rather than on syntactic variations. Our case-based diagnosis subsystem uses regular expression constructs that allow an author to specify a large number of possible variations with a single answer pattern. SWIFT can examine and evaluate any short textual answers for which cases have been designed. The author specifies patterns for classes of correct and incorrect answers, and can annotate each class with appropriate feedback and remediation information. Feedback and remediation are proven learning techniques that both motivate and improve learner retention.
This strategy still requires that the author understands the kinds of difficulties that learners can have in a particular area, and how each problem can be manifested in answers to questions. However, we have provided a framework for structuring and using that pedagogic knowledge that is both powerful and efficient enough to be used in a minimal system. SWIFT offers content authors the flexibility they need to fulfill the requirements of creating robust and meaningful cases for all situations that may occur while ensuring the rigid syntactic requirements are successfully met.
GeMS and SWIFT Mobility
Because SWIFT courses are adaptive in nature, delivery of course content must be dynamic and real-time and not just embedded within a linked or branched series of static web pages delivered once to a mobile (or desktop) device. GeMS is the cloud-based LMS which delivers the SWIFT ALE to mobile devices through a dynamic SWIFT Learning App. SWIFT Learning App links the learner through their device to the SWIFT Cloud: once a course is downloaded to SWIFT Learning App, all interactions between the learner and the course occur on the device itself which still provides dynamic content generation (and SWIFT Adaptive Learning) and, learner tracking even if the device is taken offline from network connectivity. While offline, all learner tracking and progress data is cached locally on the device; when network connectivity is restored by taking the device online, this cached data is uploaded to GeMS, allowing the learner to record their accomplishment or to continue the course on another device (including the desktop).
With GeMS and SWIFT Mobility, a learner only needs to download one dynamic app for their mobile device in order to access any SWIFT course. By separating GeMS, there is no overhead for storing course content, hosting courses for delivery, or even delivering the content to the learner — instead, organizations can focus on the results provided by the wealth of GeMS data, and integrate that learning data with other disparate sources of learning within their own organization.
Big Data Analysis – Discrimination Index and Difficulty Levels
SWIFT gathers extensive learner data that can be analyzed for all kinds of research purposes. In SWIFT, we implemented two measures to determine the effectiveness of questions and the course content. Discrimination Indexes and Difficulty Levels enable authors to refine the content and/or questions so that mastery versus non-mastery is accurately measured.
Discrimination Indexes are used to determine how well a question differentiates between high and low scorers. In other words, you should expect that the high-performing students would select the correct answer for each question more often than the low-performing students.
Difficulty Levels are used to assess how effective a test item is. By analyzing the learner data, an author can determine if the question reflects the level of difficulty intended.
Conclusion:
Mobile learning applications that will flourish and remain successful are those that can accommodate evolving learner-centric preferences, mobile standards, ubiquitous learning and the ever-changing status of knowledge and information.
SWIFT is one such mobile Platform that has evolved without comprising any of the pedagogic intelligence ensuring that investments in content will be valuable both now and far into the future.



Intelligent Tutoring Systems(ITS) have proven to be effective tools for teaching and training. However, ITSs have not become common in industrial and organizational settings, in part because their complexity has proven difficult to manage outside of the research lab. Minimalist ITSs are an attempt to bridge the gap between research and practical application; they simplify research techniques while striving to maintain as much pedagogic intelligence as possible. This paper describes one such system, SWIFT, that is an example of how a minimalist ITS can be delivered as a commercial product. We outline some of the issues facing designers of a minimalist system, and describe the ways that research techniques have been incorporated into four modules of SWIFT: adaptive testing, course planning, guidance, and diagnosis.
AI Techniques
Minimalist Design in SWIFT
The following sections describe the approaches that we have used to make; the most of the resources available to SWIFT. In general, our strategies have taken three paths: first, we have found ways to minimize ITS techniques without compromising too much of their power; second, we have found additional mechanisms to make our solutions more robust; and third, we have taken advantage of the abilities of learners and our knowledge of the eventual user population.
Knowledge Representation
A defining feature of an ITS is a semantic representation of the instructional domain, where the concepts are encoded in data structures that allow the system to reason about the course. A minimalist ITS must also employ semantic representation, for an understanding of the concepts in the domain is the basis of much of a system’s intelligent behavior. However, the detail and sophistication of the representation can vary. In SWIFT, we have implemented a presentation scheme that allows us to reason about the domain, but does not contain as much detail about specific concepts as might be found in a full ITS. SWIFT courses are stored in a hierarchical structure that divides the instructional material into smaller and smaller pieces, much as a book does with chapters, sections and subsections. A course has three levels: the first contains a set of topics, which are divided at the second level into sets of modules, which are divided at the third level into concepts. A semantic representation of the course also allows the specification of dependencies between concepts. The current version of SWIFT allows for prerequisite and sequence links between individual concept objects.
Adaptive Testing
ITSs gather information about a learner’s progress by observing them as they interact with the learning environment. Many minimalist systems use exercises, quizzes, and exams as the setting for these observations since the range of possible inference about the learner can be more easily constrained. Since many organization (corporate and otherwise) also require that a training system provides concrete records of progress, we have chosen to use formative and summative testing as our means for observing the learner in SWIFT.
One of the problems with traditional exams is that they are of fixed length; a learner must complete a long series of questions in order for the system to determine how well they know a subject. This characteristic can cause frustration for both novices and experts, who may know after a few questions that the subject matter is either bewildering or trivial. Aside from giving the learner greater control over exams – in that they are never forced to take a test – our primary strategy for tackling the problem of fixed-length exams is adaptive testing. Adaptive testing allows exams to be significantly shorter than traditional tests, without losing any predictive power about a learner’s mastery of the material. The approach that is implemented in SWIFT is based on the work of [Welch & Frick, 1993]. The algorithm uses Bayes’ theorem to estimate the probability that the learner is a master or non-master of the material after each test question is answered. In SWIFT, novices (non-masters) and experts (masters) can be determined in as few as five questions.
This graph represents the outcomes of a study that was completed comparing classroom instruction to four Intelligent Tutoring Systems. The study looked at (1) whether Tutors engender more effective and efficient learning in relation to traditional formats and (2) do they reduce the range of learning outcomes measures where a majority of individuals are elevated to high performance levels. The Tutors underwent systematic, controlled evaluations: a) Lisp tutor (Anderson Farrell & Sauers, 1984); b)Smithtown (Shute & Glaser, in press); Sherlock (Lesgold, Lajoie, Bunzo & Eggan, 1990); and d) The Pascal ITS (Bonar, Cunningham, Beatty & Weil, 1988).
Instructional Planning (ALE)
Instructional planning in SWIFT is based on two information sources: the results of an adaptive pretest, and the learner’s choice of one or more instructional goals. Each goal specifies which topics and modules of the course are to be included in the learner’s path; performance on the pretest then indicates whether concepts within those sections are already known and need not be included. Our approach to instructional planning is effective, but is relatively simple compared to some ITS (e.g. [Becht, 1990]) because of SWIFT’s less-sophisticated domain representation. Since our simpler approach weakens SWIFT’s planning to a degree, we have found other ways of ensuring that appropriate instruction is always available to the learner.
Since we knew that the target population for SWIFT is composed largely of learners that are cooperative and motivated, we were able to view instructional planning as a human-computer problem rather than just a computational one. One of the ways we involve the learner is by providing tools that allow them to monitor their path through the course, and to take control if desired. SWIFT provides an easy to navigate course map that displays the entire course and allows the learner to navigate to any topic of interest. This course map and non-linear approach also ensures that SWIFT is effective for other learning purposes such as, review or just-in-time training. This approach also improves instructional planning by making use of the knowledge of both parties: learners can improve upon or customize the system’s course plan if they wish; the recommended path, which is adequate in most cases, provides support for learners who do not wish to venture out on their own. If they do, and get lost as a result, SWIFT can take them back to where they should be with the click of a button.
Diagnosis
Diagnosis modules attempt to understand problems and misconceptions in a student’s knowledge of the domain (e.g. [Johnson & Soloway, 1985], [McCalla & Greer, 1990] ). Although any student action may be considered, diagnosis is commonly applied to a learner’s answers to test or exercise questions. Diagnosis entails drawing conclusions about the learner’s knowledge based on features in their answers; good diagnosis allows systems to provide appropriate feedback and remediation as well as simple indication of whether an answer is right or wrong. Diagnosis can require significant inferencing power and domain knowledge, which are not the strengths of minimalist systems. An alternative to a fully knowledge-based approach is to detail a number of categories, or cases, of typical errors and misconceptions. Using a case-based approach transforms the inference problem to one of classifications, but effective classification can also be difficult to achieve. One problem occurs in specifying the answers that belong to a particular class. The obvious method is to encode every answer. However, this technique implies that any variation of an answer, even those that do not change its essential parts, must also be included. This can be a daunting task for any but the most trivial of exercises.
Our approach to this problem allows a course designer to concentrate on the qualitative differences in the possible answers to a question, rather than on syntactic variations. Our case-based diagnosis subsystem uses regular expressions, constructs that allow a designer to specify a large number of possible variations with a single answer pattern. The system can examine and evaluate any short textual answers for which cases have been designed. The course designer specifies patterns for classes of correct and incorrect answers, and can annotate each class with appropriate feedback and remediation information.
This strategy still requires that the course designer understands the kinds of difficulties that learners can have in a particular area, and how each problem can be manifested in answers to questions. However, we have provided a framework for structuring and using that pedagogic knowledge that is both powerful and efficient enough to be used in a minimal system.
Situation Recognition and Guidance
SWIFT has more and more become a learner-controlled system, both by design and by necessity. In a self-directed environment, the task of the intelligent tutoring system shifts from tutoring and control to guidance and support. WE have been forced to find and implement mechanisms for supporting learners as they explore the system on their own.
We have developed a subsystem within SWIFT that can provide guidance on pedagogic issues according to the specific situation that the learner is in, and can also encourage the learner to initiate certain learning behaviours. Many strategies exist for assisting self-directed learning that promote metacognition and more effective learning behavior (eg. [Derry & Murphy, 1986], [Derry, 1992], [Pressley et al., 1989], [Shuell, 1992], [Winne, 1992]). Examples of effective learning behavior include positive self-talk, note-taking or highlighting, summation, imagery, question-generation, and review of learning objectives.
SWIFT’s guide watches system events and monitors a learner’s location, history, and current knowledge. When particular kinds of situations occur, the guide can decide to deliver advice to the learner. For example, if a student turned their attention to a new section of course material, the guide might suggest that they test their knowledge of the current section before going on. The guide is implemented as a rule-based system, and the above example would involve a rule such as “if the learner has not demonstrated mastery in the concepts of the current module, and the learner requests a move to a new module, the system will suggest that the learner take a module test for the current module.” The guide’s advice is presented in a popup dialogue box.
The rule-based guidance system provides SWIFT with a generalized architecture for presenting useful information. We are able to give the learner pedagogic guidance in a wide variety of situations, but the architecture can also be used to give information about any situation, such as tips on using SWIFT to its fullest capacity.
References
- [Brecht, 1990] Brecht (Wasson), B. (1990) Determining the Focus of Instruction: Content Planning for Intelligent Tutoring Systems, Unpublished doctoral dissertation, University of Saskatchewan.
- [Derry & Murphy, 1986] Derry, S., and Murphy, D.A. (1986), Designing Systems that Train Learning Ability: From Theory to Practice. Review of Educational Research , 56(1), 1 – 39.
- [Derry, 1992] Derry, S. (1992) Metacognitive Models of Learning and Instructional System Design. In Adaptive Learning Environments: Foundations and Frontier, M. Jones and P. Winne ed. Springer-Verlag. 257-286.
- [Johnson & Soloway, 1985] Johnson, W. L. and Soloway, E. 1985 PROUST: An Automatic Debugger for Pascal Programs. Byte, 10 (4), 179-190.
- [Pressley et al., 1989] Pressley, M. Johnson, C. Symons, S., McGoldrick , J., Kurita, J., (1989), Strategies That Improve Children’s Memory and Comprehension of Text. The Elementary School Journal, 90(1), 3-32.
- [McCall & Greer 1994] McCalla, G. I. And Greer, J.E. (1994), Granularity-Based Diagnosis and Belief Revision in Student Models, In Student Modelling: The Key to Individualized Knowledge-Based Instruction, J. Greer and G. McCalla ed, Springer-Verlag, , 39-62.
- [Winne, 1992] Winne, P. (1992) State-of-the-art Instructional Computing Systems that Afford Instruction and Bootstrap Research. In Adaptive Learning Environments: Foundations and Frontiers, M. Jones and P. Winne ed., Berlin:Springer-Verlag, 349-380.
- [Shuell, 1992] Shuell, T. J. (1992) Designing Instructional Computing Systems for Meaningful Learning. In Adaptive Learning Environments: Foundations and Frontiers, M. Jones and P. Winne ed., Berlin:Springer-Verlag, 19-54.